empiricalwiki
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 21 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
经管实证研究的 AI 知识库 — 从文献阅读到 Stata 执行,一条流水线串到底。基于 Karpathy 的 LLM-Wiki 理念,按实证研究 10 类实体(变量 / 数据集 / 模型 / 机制 / 假设 / 识别策略 / 稳健性 / 异质性 / 表格 / 论文)定制
EmpiricalWiki
Karpathy's LLM-Wiki, Specialized for Empirical Research
经管实证研究的 AI 知识库 — 从文献阅读到 Stata 执行,一条流水线串到底
From paper ingestion to Stata script — your empirical knowledge compounds, never decays.
![]()
![]()
![]()
![]()
![]()
What's New
2026-05 — Theory layer + local website view
- Theory-modeling layer. Two new page types —
assumptions(model primitives) andpropositions(theorems/results) — and a/theory-ingestskill that compiles a modeling paper into its assumptions, propositions, solution concept, and testable implications. Theory and empirics now sit on one shared graph, bridged throughmechanismsandhypotheses: the result a theory paper proves / predicts is the very mechanism / hypothesis an empirical paper tests. (Worked example: Stein 1988's managerial-myopia model now links straight to the A-share papers that test it.) Seedocs/runtime-theory-skeleton.zh.md. - Local website view.
tools/view.shrenders the wiki as a polished local site — interactive graph, full-text search, backlinks — via Quartz. One command, read-only, no Obsidian required. Seedocs/view-quartz.zh.md.

One command —
tools/view.sh — and browse the wiki locally: typed pages, backlinks, search, interactive graph. (▶ crisper MP4)

The full knowledge graph — every paper, variable, mechanism, assumption, and proposition, cross-linked.
What is EmpiricalWiki?
Andrej Karpathy proposed LLM-Wiki: an LLM that builds and maintains a persistent, structured wiki from your sources — knowledge that compounds with every paper you feed it, instead of being rediscovered on every RAG query.
EmpiricalWiki takes that idea and bends it into a single shape: empirical research in accounting, finance, management, and economics. The general LLM-wiki vision is too abstract for someone whose daily work is "怎么测耐心资本"、"哪个 IV 干净"、"双向 FE 还是公司 FE"、"Sasabuchi 拐点显著吗". EmpiricalWiki replaces the generic entity / concept / synthesis taxonomy with 10 entity types that map directly onto the empirical workflow — variables, datasets, models, mechanisms, hypotheses, identification, robustness, heterogeneity, tables, and papers.
Drop your .pdf files in a folder. Run one command. Get a wiki where every paper's variable construction, model setup, identification strategy, and robustness battery is broken out, cross-referenced, and queryable — and where the next time you read a paper that operationalizes a construct differently from the last one, the new variant lands on the same variable page next to the earlier ones.
Why Empirical-Specialized, Not Generic?
| RAG | Generic LLM-Wiki | EmpiricalWiki | |
|---|---|---|---|
| Knowledge persistence | Rediscovered every query | Compiled once | Compiled once |
| Structure | Flat chunk store | 9 generic entity types | 10 empirical-flow entity types |
| Variable construction | Lost across queries | Buried in concept pages |
First-class variables/ with measurement formula, data source, project paths |
| Identification strategy | Not extracted | Generic concept page |
First-class identification/ page with assumptions, threats, diagnostics |
| Robustness battery | Not extracted | Mixed in summary | First-class robustness/ page with check type and expected pattern |
| Cross-paper variant comparison | None | Manual | Automatic — A1/A2/A3/A4/B1/B2/C/D variants accumulate on one variable page |
| Output | Chat answers | Surveys, paper drafts | Surveys + paper drafts +Stata execution plans |
| Compounding | No | Yes | Yes — each paper enriches the variable / identification / robustness libraries |
Architecture
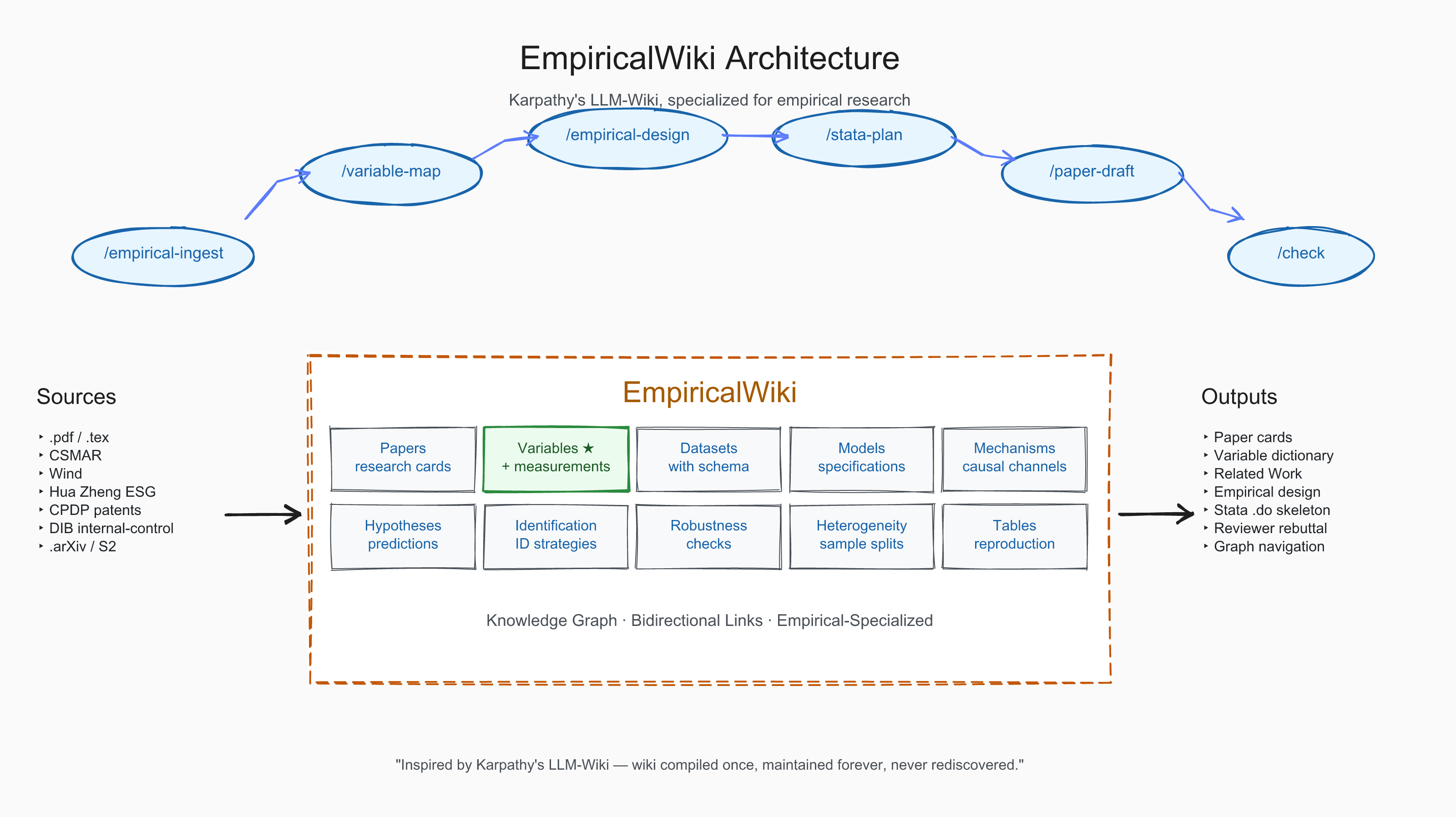
Three layers, faithful to Karpathy's original gist:
- Raw —
raw/papers/holds your PDFs unchanged. Reading is read-only; the LLM never edits source. - Wiki —
wiki/is the LLM-maintained, compounding artifact: empirical pages (variables, models, identification …), a theory layer (assumptions,propositions), and one graph that bridges theory and empirics throughmechanisms/hypotheses. Every page is markdown with strict frontmatter, written and rewritten by ingest skills. - Schema —
CLAUDE.md+.claude/skills/define how the LLM should read, write, and link. 29 slash commands, all of them reading from and writing back to the wiki.
Every skill reads from and writes back to the same wiki. Knowledge compounds — each new paper enriches the variable, identification, and theory libraries and the cross-paper graph. Failed measurements aren't discarded; the variant goes into the variable's Literature Variants section. To browse it all, tools/view.sh renders the wiki as a local website (graph / search / backlinks) via Quartz.
配套图书:《EmpiricalWiki 实战手册——从 Karpathy LLM Wiki 到实证》
配套手册一本,介绍 EmpiricalWiki 的设计依据、工作流程与具体使用方式。共 8 章。
| 章 | 标题 |
|---|---|
| 第 1 章 | 一个 1945 年提出至今没解决的问题 |
| 第 2 章 | Karpathy 提的那个新思路,到底新在哪里 |
| 第 3 章 | 三层架构在 EmpiricalWiki 里长什么样 |
| 第 4 章 | 一篇实证论文,能被拆成多少个零件 |
| 第 5 章 | 28 个命令构成的工作流 |
| 第 6 章 | 第一篇文献的摄入:5 分钟里发生了什么 |
| 第 7 章 | 跨论文累积:一张变量页面如何从一段长到八段 |
| 第 8 章 | 从文献到论文:研究设计与 Stata 计划 |
本书暂不公开发行;如有获取需要,请联系作者。
Quick Start
Prerequisites: Python 3.9+, Node.js 18+
# 1. Get the project
git clone https://github.com/Lambenthan/empiricalwiki.git
cd empiricalwiki
# 2. Install Claude Code
npm install -g @anthropic-ai/claude-code
claude login
# 3. One-click setup
chmod +x setup.sh && ./setup.sh # Linux / macOS
# Windows (PowerShell):
# powershell -ExecutionPolicy Bypass -File .\setup.ps1
# setup creates .venv for EmpiricalWiki and registers tools/_env.py
# 4. Drop your literature into raw/papers/
# .pdf is fine; .tex is preferred when available
# Optional: raw/notes/research-intent.md to record your project goal
# 5. Build your wiki
claude
# Then type: /empirical-ingest <pdf-path> to ingest one paper
# Or: /init [your-research-topic] to bootstrap from a literature batch
python3 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
cp .env.example .env # Edit to add API keys
cp config/settings.local.json.example .claude/settings.local.json
python -m venv .venv
.\.venv\Scripts\Activate.ps1
pip install -r requirements.txt
Copy-Item .env.example .env # Edit to add API keys
Copy-Item config\settings.local.json.example .claude\settings.local.json
Native Windows is supported for the local pipeline. Remote-GPU experiments via /exp-run --env remote rely on ssh/rsync/screen and run best from WSL2 or Linux/macOS.
API Keys
| Key | Required? | How to get | What it enables |
|---|---|---|---|
ANTHROPIC_API_KEY |
Yes | claude login (automatic) |
Powers all Claude Code skills |
SEMANTIC_SCHOLAR_API_KEY |
Optional | semanticscholar.org/product/api (free) | Citation graph, paper search |
DEEPXIV_TOKEN |
Optional | setup.sh auto-registers |
Semantic search, TLDR, trending |
LLM_API_KEY + LLM_BASE_URL + LLM_MODEL |
Optional | Any OpenAI-compatible API | Cross-model review |
Cross-model review: EmpiricalWiki uses a second LLM as an independent reviewer for ideas, experiments, and paper drafts. Works with any OpenAI-compatible API — DeepSeek, OpenAI, Qwen, OpenRouter, SiliconFlow, etc. If not configured, skills still work in Claude-only mode.
Skills
29 slash commands. Five of them — /empirical-ingest, /theory-ingest, /variable-map, /empirical-design, /stata-plan — are EmpiricalWiki's own additions; the rest are inherited from the upstream LLM-Wiki framework and adapted to the empirical workflow.
Phase 0: Setup
| Command | What it does |
|---|---|
/setup |
First-time configuration (API keys, language, dependencies) |
/reset <scope> |
Destructive cleanup:wiki | raw | log | checkpoints | all |
Phase 1: Empirical Knowledge Foundation
| Command | What it does |
|---|---|
/prefill <domain> |
Optionally seed foundations/ with textbook background (causal inference / panel methods / etc.) |
/init [topic] |
Bootstrap a full wiki from your raw/papers/ literature folder |
/empirical-ingest <pdf> |
Empirical-specific — parse one paper into papers + variables + datasets + models + mechanisms + identification + robustness + heterogeneity + edges |
/theory-ingest <pdf> |
Theory-specific — parse a modeling paper into assumptions + propositions + solution concept + testable implications, bridged to the empirical layer |
/ingest <source> |
Generic ingest (preferred when the paper isn't strictly empirical) |
/discover |
Recommend ranked next-read papers from anchors, a topic, or the current wiki |
/variable-map "<construct>" |
Empirical-specific — aggregate all measurement variants of one construct (e.g. 耐心资本) across the wiki, with data source + project availability |
/edit <request> |
Add/remove sources or update wiki content |
/ask <question> |
Query the wiki, crystallize answers back |
/check |
Health scan: broken links, missing cross-refs, consistency |
Phase 2: Research Design & Execution
| Command | What it does |
|---|---|
/empirical-design <topic> |
Empirical-specific — generate research question, variable design, model setup, mechanism, heterogeneity, robustness, and data-gap report |
/stata-plan <design> |
Empirical-specific — turn a research design into a Stata execution plan; --write-do produces a .do skeleton |
/daily-arxiv |
Auto-fetch & filter new arXiv papers (+ GitHub Actions cron) |
/ideate |
Multi-phase idea generation from cross-topic connections |
/novelty <idea> |
Multi-source novelty verification (web + S2 + wiki + review LLM) |
/review <artifact> |
Cross-model adversarial review for any research artifact |
/exp-design <idea> |
Claim-driven experiment + ablation design |
/exp-run <experiment> |
Implement + deploy + monitor (local or remote GPU) |
/exp-status |
Dashboard for running experiments; auto-collect results |
/exp-eval <experiment> |
Verdict gate → auto-update claims/ideas/graph |
/refine <artifact> |
Multi-round: produce → review → fix → re-review |
Phase 3: Writing & Submission
| Command | What it does |
|---|---|
/survey |
Generate Related Work from wiki knowledge |
/paper-plan <claims> |
Outline from claim graph + evidence matrix |
/paper-draft <plan> |
Draft LaTeX + figures, section by section |
/paper-compile <dir> |
Compile → PDF, auto-fix, verify page/anonymity |
/research <direction> |
End-to-end orchestrator with human gates |
/rebuttal <reviews> |
Parse reviewer comments → draft point-by-point responses |
Wiki Structure
10 Empirical Entity Types
The 10 entities below replace the generic entity / concept / synthesis taxonomy with one that maps directly onto the empirical research workflow.
| Type | Directory | Purpose |
|---|---|---|
| Paper | papers/ |
Structured empirical card: 研究问题 / 理论机制 / 研究假设 / 数据与样本 / 变量设定 / 模型设定 / 主要结果 / 机制检验 / 异质性检验 / 稳健性检验 / 内生性处理 / 可复现线索 / 对我当前选题的启发 |
| Variable | variables/ |
One construct per page (e.g. 耐心资本),measurement formula, data source, role (DV / IV / mediator / moderator / control), Stata snippet,Literature Variants section accumulating across-paper differences |
| Dataset | datasets/ |
One database per page (CSMAR / Wind / 华证 ESG / CPDP 专利 …),coverage, fields, merge keys, cleaning rules, missingness |
| Model | models/ |
One specification per page (双向 FE / 多期 DID / IV-2SLS …),equation, identification logic, FE structure, SE clustering, Stata skeleton |
| Mechanism | mechanisms/ |
One causal channel per page (管理者短视中介 / 融资约束中介 / 代理成本中介 …),theoretical logic, empirical proxy, evidence across papers |
| Hypothesis | hypotheses/ |
One testable prediction per page (e.g. PC → 探索式创新 +),with literature basis, testable model, evidence list |
| Identification | identification/ |
One strategy per page (IV / Heckman / PSM / DID …),assumptions, threats, implementation, diagnostics |
| Robustness | robustness/ |
One check per page (Sasabuchi U-shape / placebo / sub-period / alternative DV …),purpose, when to use, expected table pattern |
| Heterogeneity | heterogeneity/ |
One split per page (产权 / 行业 / 地区 / 规模 …),grouping rule, theoretical rationale, sample split |
| Table | tables/ |
One reproduction target per page; columns, key coefficients, interpretation, reproduction notes |
The general LLM-wiki types (concepts/ / topics/ / claims/ / ideas/ / experiments/ / people/ / Summary/ / foundations/) remain available for non-empirical content (theory papers, methodology surveys, your own research ideas).
Bidirectional Wikilinks
Every forward link (papers/A → variables/V, type=operationalizes) is paired with a reverse link in the same write. The graph in wiki/graph/edges.jsonl is the canonical source for cross-entity relationships; wiki/graph/citations.jsonl records bibliographic citations separately.
Edge types specific to the empirical layer:operationalizes (paper → variable) ·uses_dataset (paper → dataset) ·estimates_model (paper → model) ·tests_mechanism (paper → mechanism) ·tests_hypothesis (paper → hypothesis) ·addresses_endogeneity_with (paper → identification) ·uses_robustness_check (paper → robustness) ·uses_heterogeneity_split (paper → heterogeneity) ·reports_table (paper → table)
All pages use Obsidian [[wikilink]] format — open wiki/ in Obsidian for visual graph exploration.
What This Looks Like in Practice
For an empirical project, EmpiricalWiki produces:
- One paper card per ingested PDF — full extraction of research question, hypotheses, sample, variables, model, identification, robustness, heterogeneity
- Variable pages that accumulate measurement variants across papers — when one paper operationalizes a construct differently from another, the new variant lands on the same page, side by side, instead of being lost in chat history
- Reusable identification / robustness / heterogeneity libraries — cross-paper patterns become first-class, searchable entities
- A bidirectional graph linking papers ↔ variables ↔ datasets ↔ models ↔ mechanisms, materialized in
wiki/graph/edges.jsonl
When you next read a paper using a construct you've seen before, you don't need to remember which earlier paper used which operationalization — the variable page already has every variant you've encountered, with source_papers pointing to the originating cards.
Project Structure
EmpiricalWiki/
├── CLAUDE.md # Runtime schema & rules (the schema layer)
├── README.md # This file
├── README_EMPIRICAL.md # Adaptation note (how this fork differs from upstream)
├── llm_wiki_relationship.excalidraw # Karpathy ↔ EmpiricalWiki 对应关系图
├── llm_wiki_relationship_script.md # 配套讲解稿
├── wiki/ # Knowledge base (LLM-maintained — the wiki layer)
│ ├── papers/ # Empirical paper cards (20 ingested)
│ ├── variables/ # Constructs + measurement variants (37)
│ ├── datasets/ # Database documentation (10)
│ ├── models/ # Specification cards (5)
│ ├── mechanisms/ # Causal channels (24)
│ ├── hypotheses/ # Testable predictions (7)
│ ├── identification/ # Endogeneity strategies (16)
│ ├── robustness/ # Robustness check designs (9)
│ ├── heterogeneity/ # Sample splits & moderators (24)
│ ├── tables/ # Table reproduction notes
│ ├── concepts/ # Generic concepts (when not empirical)
│ ├── topics/ # Research direction maps
│ ├── people/ # Researcher profiles
│ ├── ideas/ # Your own research ideas
│ ├── experiments/ # For computational/simulation work
│ ├── claims/ # Standalone claims with evidence
│ ├── Summary/ # Domain surveys
│ ├── foundations/ # Textbook background
│ ├── outputs/ # Generated artifacts (drafts, plots)
│ ├── graph/ # Auto-generated: edges, citations, gaps
│ ├── index.md # Content catalog
│ └── log.md # Append-only chronological log
├── raw/ # Source materials (the raw layer — read-only by ingest)
│ ├── papers/ # Your .pdf / .tex literature
│ ├── discovered/ # /init and /daily-arxiv downloads
│ ├── tmp/ # Generated prepared sidecars
│ ├── notes/ # Your .md research notes
│ └── web/ # Saved HTML / Markdown
├── tools/ # Deterministic Python helpers
│ ├── research_wiki.py # Wiki engine (slug, add-edge, rebuild-index, ...)
│ ├── prepare_paper_source.py # PDF → tex preparation
│ ├── init_discovery.py # /init download helper
│ ├── discover.py # /discover candidate gathering & ranking
│ ├── lint.py # Structural validation
│ ├── reset_wiki.py # Scoped destructive cleanup
│ ├── fetch_arxiv.py # arXiv RSS fetcher
│ ├── fetch_s2.py # Semantic Scholar API
│ ├── fetch_deepxiv.py # DeepXiv semantic search
│ ├── fetch_wikipedia.py # Wikipedia fetcher
│ └── remote.py # SSH for remote experiments
├── .claude/skills/ # 29 Claude Code skill definitions
├── docs/ # Runtime page templates & graph format docs
├── i18n/ # Bilingual: en/ + zh/
├── config/ # Configuration templates
├── mcp-servers/ # Cross-model review server
└── .github/workflows/ # Daily arXiv cron
Bilingual Support
EmpiricalWiki ships in English and Chinese. The Chinese version is recommended for empirical research workflows since most CSMAR / Wind / 华证 ESG terminology is Chinese-native.
./setup.sh --lang zh # 中文(推荐)
./setup.sh --lang en # English
Roadmap
- 10 empirical-specific entity types
- 4 empirical-specific skills (
/empirical-ingest,/variable-map,/empirical-design,/stata-plan) - End-to-end pipeline validated on a real empirical research project
- Bidirectional wikilink + graph layer for empirical edges
- Bilingual i18n (EN + ZH)
- Pre-built Stata template library (PSM / DID / IV / 双向 FE)
- CSMAR / WRDS / 华证 ESG schema cards in
datasets/ - Demo wiki for non-PC topics (managerial myopia, ESG performance, ...)
- Multi-user collaboration
Contributing
Issues and PRs welcome. See CONTRIBUTING.md. Empirical-specific contributions especially appreciated:
- New
datasets/cards for databases not yet documented - New
identification/cards for endogeneity strategies common in your subfield - New
robustness/cards for checks not in the current library
LLM API Configuration / 大模型 API 配置
EmpiricalWiki runs on Claude Code, which speaks the Anthropic API protocol. You can use Claude directly, or route Claude Code to any third-party provider that exposes an Anthropic-compatible endpoint by overriding a few environment variables.
EmpiricalWiki 基于 Claude Code,Claude Code 使用 Anthropic API 协议通信。你既可以直接使用 Claude,也可以通过覆盖几个环境变量,把 Claude Code 指向任意支持 Anthropic 协议的第三方供应商。
Option A — Native Claude / 原生 Claude
claude login # OAuth, no manual config / OAuth 登录,无需手动配置
Option B — Third-party Anthropic-compatible API / 第三方 Anthropic 兼容 API
Pick a provider below, paste the snippet into ~/.claude/settings.json (or the project's .claude/settings.json), and replace the <...> placeholder with your own API key.
从下方任选一个供应商,把对应配置粘贴到 ~/.claude/settings.json(或项目的 .claude/settings.json),并把 <...> 占位符替换为你自己的 API key。
MiMo (小米)
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.xiaomimimo.com/anthropic",
"ANTHROPIC_AUTH_TOKEN": "<your-mimo-key>",
"ANTHROPIC_MODEL": "mimo-v2.5",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "mimo-v2.5",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "mimo-v2.5-pro",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "mimo-v2.5"
}
}
DeepSeek
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.deepseek.com/anthropic",
"ANTHROPIC_AUTH_TOKEN": "<your-deepseek-key>",
"ANTHROPIC_MODEL": "deepseek-v4-pro[1m]",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "deepseek-v4-pro[1m]",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-v4-pro[1m]",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-v4-flash",
"CLAUDE_CODE_SUBAGENT_MODEL": "deepseek-v4-flash",
"CLAUDE_CODE_EFFORT_LEVEL": "max"
}
}
Kimi (Moonshot)
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.moonshot.ai/anthropic",
"ANTHROPIC_AUTH_TOKEN": "<your-moonshot-key>",
"ANTHROPIC_MODEL": "kimi-k2.5",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "kimi-k2.5",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "kimi-k2.5",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "kimi-k2.5",
"CLAUDE_CODE_SUBAGENT_MODEL": "kimi-k2.5",
"ENABLE_TOOL_SEARCH": "false"
}
}
GLM (Z.AI)
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.z.ai/api/anthropic",
"ANTHROPIC_AUTH_TOKEN": "<your-zai-key>",
"API_TIMEOUT_MS": "3000000"
}
}
Z.AI applies a default server-side model mapping, so no explicit
ANTHROPIC_MODELis needed.
Z.AI 默认在服务端做模型映射,无需显式设置ANTHROPIC_MODEL。
Skip the Claude Code onboarding / 跳过 Claude Code 初始引导
When using a third-party key (instead of claude login), Claude Code's first-run onboarding won't complete automatically. Create or edit .claude.json and mark it done:
使用第三方 key 时不会走 claude login,Claude Code 首次启动的引导不会自动完成。创建或编辑 .claude.json,手动标记引导已完成:
- macOS / Linux:
~/.claude.json - Windows:
<user-home>\.claude.json
{
"hasCompletedOnboarding": true
}
Then run claude as usual. / 保存后正常运行 claude 即可。
Acknowledgments
- ΩmegaWiki — EmpiricalWiki is a downstream specialization of the upstream ΩmegaWiki framework by DAIR Lab at Peking University. The three-layer architecture, the bidirectional wikilink convention, the cross-model review pattern, and 24 of the 29 skills come straight from upstream. EmpiricalWiki adds 5 specialized skills (4 empirical —
/empirical-ingest,/variable-map,/empirical-design,/stata-plan; plus 1 theory —/theory-ingest), a theory-modeling layer, and replaces the entity taxonomy. Thanks for building the foundation. - Andrej Karpathy — for the LLM-Wiki gist that articulated the pattern: raw / wiki / schema, ingest / query / lint, "the wiki is the artifact, not the chat."
- Claude Code — the AI agent runtime that powers EmpiricalWiki.
License
MIT — use it, fork it, build on it.
中文
最新更新
2026-05 — 理论层 + 本地网站展示
- 理论建模层。 新增两类页面 ——
assumptions(模型原语)与propositions(命题/定理),以及/theory-ingestskill,把一篇建模论文消化成它的假设、命题、解概念与可检验推论。理论与实证现在同处一张图谱,通过mechanisms与hypotheses接桥:一篇理论论文所证明 / 预测的机制和假设,正是实证论文所检验的那一个。(实例:Stein 1988 的管理者短视模型,直接连到检验它的中国 A 股论文。)详见docs/runtime-theory-skeleton.zh.md。 - 本地网站展示。
tools/view.sh用 Quartz 把 wiki 渲染成一个本地网站 —— 交互式图谱、全文搜索、反向链接。一条命令、只读、不用装 Obsidian。详见docs/view-quartz.zh.md。
EmpiricalWiki 是什么?
Andrej Karpathy 提出了 LLM-Wiki 概念:让 LLM 构建并维护一个持久的、结构化的 wiki,而不是一次性的 RAG 回答。每读一篇论文,整个知识图就更厚一点。
EmpiricalWiki 把这个概念掰到一个具体方向上:会计、金融、管理、经济学的实证研究。 通用的 LLM-wiki 设想对一个每天思考"耐心资本怎么测"、"哪个 IV 干净"、"双向 FE 还是公司 FE"、"Sasabuchi 拐点显不显著"的人来说太抽象了。EmpiricalWiki 把通用的 entity / concept / synthesis 三类换成 直接对应实证研究流程的 10 类实体 —— variables、datasets、models、mechanisms、hypotheses、identification、robustness、heterogeneity、tables、papers。
把你的 PDF 丢进文件夹。跑一条命令。得到一个 wiki:每一篇论文的变量构造、模型设定、识别策略、稳健性检验全部被抽出来、互相打通、随时可查。当你下一次读到一篇用了跟之前不一样的方法测某个构念的论文,这个新变体会被加到同一个变量页面里,跟前面看过的并列摆好,而不是丢失在某段聊天记录里。
为什么要做经管特化版?
| RAG | 通用 LLM-Wiki | EmpiricalWiki | |
|---|---|---|---|
| 知识持久性 | 每次重新检索 | 一次编译 | 一次编译 |
| 结构 | 扁平 chunk | 9 类通用实体 | 10 类按实证流程的实体 |
| 变量构造 | 跨查询丢失 | 埋在 concept 页 | 一等公民 variables/(含公式 + 数据源 + 项目路径) |
| 识别策略 | 不被抽取 | 通用 concept 页 | 一等公民 identification/(含假设 + 威胁 + 诊断) |
| 稳健性套餐 | 不被抽取 | 混在摘要里 | 一等公民 robustness/(含检验类型 + 期望表格模式) |
| 跨论文变体对比 | 没有 | 手动 | 自动 — A1/A2/A3/A4/B1/B2/C/D 累积在同一变量页 |
| 输出 | 聊天回答 | 综述 + 论文草稿 | 综述 + 论文草稿 +Stata 执行计划 |
| 复利 | 无 | 有 | 有 — 每篇论文丰富 variable / identification / robustness 三个库 |
三层架构
EmpiricalWiki 严格遵循 Karpathy 原始 gist 的三层结构:
- Raw —
raw/papers/放你的 PDF,ingest 永远只读不写。 - Wiki —
wiki/是 LLM 维护、不断累积的产物:实证页(变量/模型/识别…)、理论层(assumptions、propositions),以及一张通过mechanisms/hypotheses把理论与实证接在一起的图谱。每个实体页都是 markdown + 强制 frontmatter,被 ingest skill 写入和重写。 - Schema —
CLAUDE.md+.claude/skills/定义 LLM 怎么读、怎么写、怎么打链。29 个 slash command,全部读自 wiki、写回 wiki。用tools/view.sh可把整个 wiki 渲染成带图谱/搜索/反链的本地网站。
快速开始
前置条件: Python 3.9+, Node.js 18+
git clone https://github.com/Lambenthan/empiricalwiki.git && cd empiricalwiki
# 安装 Claude Code
npm install -g @anthropic-ai/claude-code
claude login
# 一键配置
chmod +x setup.sh && ./setup.sh --lang zh # Linux / macOS
# Windows (PowerShell):
# powershell -ExecutionPolicy Bypass -File .\setup.ps1 -Lang zh
# 把你的论文放入 raw/papers/(.pdf 或 .tex)
# 启动 Claude Code
claude
# 然后输入:/empirical-ingest <PDF 路径> 消化一篇论文
# 或者: /init [研究主题] 批量初始化
Windows 用户:本地 pipeline 已原生支持。
/exp-run --env remote远程 GPU 实验依赖ssh/rsync/screen,建议在 WSL2 或 Linux/macOS 下运行(经管实证一般用不上)。
API Key 说明
| Key | 必须? | 获取方式 | 用途 |
|---|---|---|---|
ANTHROPIC_API_KEY |
是 | claude login |
驱动所有 Skill |
SEMANTIC_SCHOLAR_API_KEY |
可选 | semanticscholar.org(免费) | 引用图谱、论文搜索 |
DEEPXIV_TOKEN |
可选 | setup.sh 自动注册 |
语义搜索、热门趋势 |
LLM_API_KEY + LLM_BASE_URL + LLM_MODEL |
可选 | 任意 OpenAI 兼容 API | 跨模型评审 |
29 个 Skill(经管 + 理论特化)
| 命令 | 功能 |
|---|---|
/setup |
首次配置(API key、语言、依赖) |
/reset |
按范围销毁性清理:wiki | raw | log | checkpoints | all |
/prefill |
可选地预填 foundations/ 教科书背景(因果推断 / 面板方法 / ...) |
/init |
基于 raw/papers/ 文献批量搭建 wiki |
/empirical-ingest |
经管特化 — 把一篇论文消化成 papers + variables + datasets + models + mechanisms + identification + robustness + heterogeneity + edges |
/theory-ingest |
理论特化 — 把一篇建模论文消化成 assumptions + propositions + 解概念 + 可检验推论,并与实证层接桥 |
/ingest |
通用消化(非纯实证论文用这个) |
/discover |
从 anchor、topic 或当前 wiki 推荐排序后的下一批待读论文 |
/variable-map |
经管特化 — 汇总某个构念在 wiki 里的全部测算变体(含数据源 + 项目可用性) |
/edit |
增删 raw 或更新 wiki |
/ask |
对 wiki 提问 |
/check |
wiki 健康检查(双向链接对称性 / 孤立实体 / 字段合规) |
/empirical-design |
经管特化 — 输出研究问题 + 变量设计 + 模型 + 机制 + 异质性 + 稳健性 + 数据缺口 |
/stata-plan |
经管特化 — 把研究方案转成 Stata 执行计划,--write-do 给出 .do 骨架 |
/daily-arxiv |
每日 arXiv 新论文 |
/ideate |
跨方向构思研究 idea |
/novelty |
多源新颖性验证 |
/review |
跨模型评审 |
/exp-design |
Claim 驱动实验设计(计算实验/仿真用) |
/exp-run |
部署 + 监控实验 |
/exp-status |
实验状态看板 |
/exp-eval |
裁决 → 更新 claims |
/refine |
多轮迭代改进 |
/survey |
生成 Related Work |
/paper-plan |
Claim 图谱 → 论文提纲 |
/paper-draft |
提纲 + wiki → LaTeX 草稿 |
/paper-compile |
编译 → PDF,自动修复 |
/research |
端到端研究编排器 |
/rebuttal |
解析评审意见 → 逐条回复 |
10 类经管实证实体
详细模板见 docs/runtime-page-templates.zh.md。简要对应:
| 实体 | 目录 | 用途 |
|---|---|---|
| Paper | papers/ |
实证论文卡片(14 节正文:研究问题 / 理论机制 / 假设 / 数据 / 变量 / 模型 / 主结果 / 机制 / 异质性 / 稳健性 / 内生性 / 可复现 / 启发 / Related) |
| Variable | variables/ |
一个构念一页,含测算公式、数据源、Stata snippet、Literature Variants 章节自动累积跨论文差异 |
| Dataset | datasets/ |
一个数据库一页(CSMAR / Wind / 华证 ESG / CPDP 专利…),含覆盖范围、字段、合并 key、清洗规则、缺失情况 |
| Model | models/ |
一种设定一页(双向 FE / 多期 DID / IV-2SLS …) |
| Mechanism | mechanisms/ |
一条因果通道一页(管理者短视中介 / 融资约束中介 / 代理成本中介 …) |
| Hypothesis | hypotheses/ |
一条可检验预测一页 |
| Identification | identification/ |
一种识别策略一页(IV / Heckman / PSM / DID …) |
| Robustness | robustness/ |
一项稳健性检验一页(Sasabuchi / placebo / 子样本 / 替换 DV …) |
| Heterogeneity | heterogeneity/ |
一种切分一页(产权 / 行业 / 地区 / 规模 …) |
| Table | tables/ |
一张表的复现要点 |
通用类型 (concepts/ / topics/ / claims/ / ideas/ / experiments/ / people/ / Summary/ / foundations/) 仍保留给非实证内容(理论论文、方法论综述、自有研究 idea)。
EmpiricalWiki 在实证项目里长什么样
对一个实证研究项目而言,EmpiricalWiki 产出的是:
- 一篇论文一张实证卡片 —— 研究问题、假设、样本、变量、模型、识别、稳健性、异质性都被抽取出来
- 跨论文累积测算变体的变量页 —— 第二篇用了跟第一篇不一样的操作化方式,新变体直接落在同一页,并列展示,而不是丢失在某段聊天记录里
- 可复用的识别策略 / 稳健性 / 异质性库 —— 跨论文重复出现的设计模式被抽成独立的可检索实体
- 双向链接的图谱:papers ↔ variables ↔ datasets ↔ models ↔ mechanisms,物化在
wiki/graph/edges.jsonl
下一次再读用了某个已知构念的论文时,不用回忆之前哪篇用了哪种操作化 —— 变量页里所有见过的变体早就并列摆好了,每条挂着 source paper。
致谢
- ΩmegaWiki —— EmpiricalWiki 是 ΩmegaWiki 在经管实证方向上的下游特化版本,三层架构、双向链接、跨模型评审、29 个 skill 中的 24 个全部来自上游 DAIR Lab(北京大学)。EmpiricalWiki 在此基础上加了 5 个特化 skill(4 个经管 + 1 个理论
/theory-ingest)并替换了实体分类、新增理论建模层。感谢上游团队搭好的地基。 - Andrej Karpathy —— 提出 LLM-Wiki gist,明确了 raw / wiki / schema 三层架构与 ingest / query / lint 三个操作。
- Claude Code —— 驱动 EmpiricalWiki 的 AI agent runtime。
Built with Claude Code
If this project helps your empirical research, give it a ⭐
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found